
Have you ever been happily gathering information from a website, only to suddenly hit a wall? You see a message like “Access Denied” or the page simply stops loading. It’s frustrating, and it feels like the website has slammed a digital door in your face. This isn’t a glitch; it’s a security measure, and getting around it requires a clever disguise, not a password. Find the best proxies for linkedin.
Think of websites as establishments with a bouncer at the door. This bouncer’s job is to prevent any one person from making too many requests too quickly, which can slow the site down for everyone. To do this, they check every visitor’s unique identification: their IP address. In practice, your IP address acts like a digital mailing address, telling every website exactly where the information should be sent back to.
When you make too many visits from the same address in a short time, the bouncer recognizes you and blocks you. This is the most common reason people encounter an access denied message when trying to collect data. To continue your work, you can’t just knock on the door again; you need to look like a completely new visitor. This is the key to successful web scraping without getting banned.
That’s where a special tool comes in. Imagine you could send your request through a mail-forwarding service that puts a different return address on your package each time. On the internet, this service is called a proxy. Using proxies for scraping gives you a new digital address for each connection, making you appear as a different person every time. This simple change allows you to gather the data you need, no matter how many times the bouncer is watching the door.
Your IP Address: The “Caller ID” That Gets You Blocked
To understand why you get blocked, you first need to know about your digital footprint. Every time you connect to the internet, your device is assigned a unique identifier called an IP address. The simplest way to think of it is as your home’s mailing address, but for the internet. When you visit a website, you’re essentially sending them a request for information, and your IP address tells their server where to send that information back. Websites see this “return address” for every single visitor, including you.
This “digital address” is the primary reason you get blocked. Websites are wary of automated bots that try to scrape data too quickly, as it can slow down their service for real human users. If hundreds of requests hit their server from the same IP address in just a few seconds—an obvious sign of a bot, not a person—they’ll put up a virtual wall. This defensive action is a concept known as rate limiting, and it’s one of the most common hurdles for anyone trying to gather data.
Beyond just speed, your IP address also reveals your approximate physical location. Have you ever noticed that a shopping website automatically shows you prices in your local currency? That’s geo-location at work. This same technology can be used to block you entirely. If you’re trying to view content that’s only available to users in another country, the website will see your IP address, know you’re not in the right place, and deny you access. Understanding what is an ip address and how it’s used is the first step in learning how to avoid ip blocks when scraping.
Introducing Your Secret Weapon: How a Proxy Server Works
Knowing your IP address is the reason you get blocked raises a big question: how do you get around it? Imagine you wanted to send a letter to a company that has blocked mail from your home address. You could use a mail-forwarding service. You’d send your letter to them, they’d put it in a new envelope with their return address, and send it along. On the internet, this helpful middleman is called a proxy server. It’s an intermediary computer that sits between you and the websites you visit.
The process of using a proxy is surprisingly simple. Instead of your computer connecting directly to a website, it first connects to the proxy server. You tell the proxy, “Go get the data from that flight website.” The proxy then visits the website for you. To the flight website, it just looks like a regular visitor, and it only sees the proxy’s IP address. Your own IP address is never revealed, keeping your digital identity private and off any potential blocklists. This is the fundamental principle of how proxies work: they lend you their address.
This simple act of redirection is the key to overcoming IP blocks. When you’re using proxies for web scraping, if a website flags and blocks one of your proxy’s IP addresses, it’s not a problem. You just send your next request through a different proxy, which has a brand-new IP address. To the website, it looks like a completely new person just arrived. But not all proxies are created equal; some act like a cheap disguise while others are masters of stealth. Understanding the difference is crucial for your project.
Datacenter vs. Residential Proxies: Choosing Your Disguise
Now that you know a proxy can act as your disguise, it’s time to choose one. The most common and affordable type is the Datacenter Proxy. Think of these proxies as IP addresses located in a massive, commercial office building. They are incredibly fast and efficient because they’re built for high-speed business operations. However, websites can easily check the address and see it belongs to a corporation, not a home. This makes them instantly suspicious. It’s like trying to blend into a casual party while wearing a uniform that says “Server Staff.”
For situations where you need to blend in perfectly, there’s a more powerful option: the Residential Proxy. Instead of an address in an office park, a residential proxy gives you an IP address that belongs to a real home. It’s an address assigned by a standard Internet Service Provider (like Comcast, Verizon, or AT&T) to a real person’s device. When a website sees a request coming from one of these, it has no reason to be suspicious. To them, it looks just like you or me browsing from our living room, making it the ultimate form of camouflage.
So, what’s the catch? It comes down to a classic trade-off between speed and stealth. Datacenter proxies are the sprinters—fast, cheap, and great for simple tasks on websites with low security. But because they are easily identified, they get blocked more often. Residential proxies are the spies—slower and more expensive, but their genuine appearance lets them slip past the toughest security measures. This is the core choice in residential vs datacenter proxies for web scraping.
Choosing the best proxy service for data extraction depends entirely on your target. If you’re grabbing a few prices from a simple site, a datacenter proxy might be all you need. But for gathering large amounts of data from a sophisticated platform like Amazon or an airline, the stealth of a residential proxy is essential. The problem, however, is that even the best disguise becomes suspicious if you show up at the same door a hundred times in a minute. What you really need is an endless supply of disguises.
Never Use the Same Disguise Twice: The Power of Rotating Proxies
We’ve established that using a residential proxy is like wearing a perfect disguise. But even the best disguise becomes suspicious if you show up at the same location a hundred times in a minute. Websites are smart; they track not just who is visiting (your IP address) but also how often they visit. If one IP address makes too many requests too quickly, the site will block it, no matter how legitimate it looks. This is a major roadblock when you need to gather a lot of information.
The solution is to have an endless supply of disguises. Imagine that instead of one spy, you have a whole team spread across the country. For every single piece of data you need, you send a different person. This is exactly what is a rotating proxy does. It’s a system that automatically swaps your IP address for a new one with every request you make, pulling from a huge collection called a proxy pool. To the website, it never looks like one person is making a thousand requests; it looks like a thousand different people are each making one.
This automated rotation is the key to web scraping without getting banned on a large scale. It allows you to collect vast amounts of information—like thousands of product prices or customer reviews—while appearing as normal, organic traffic. Professional-grade proxy pool management for large-scale scraping handles all this switching for you, making your project seem like a gentle stream of individual visitors instead of a tidal wave from a single source. This technology also unlocks another incredible capability: choosing the physical location of your disguise.
How to See a Website As If You’re in Another Country
That ability to choose your disguise’s location is more than just a clever trick; it’s a solution to a common internet hurdle. Have you ever noticed that a product is available in the UK but not in the US, or that a streaming service has a different library of shows when you’re on vacation? This happens because websites check your IP address to determine your location and then serve you different content. This practice is known as geo-restriction or geo-blocking.
This is where the true power of a global proxy network shines. When you use a proxy, you’re not just hiding your IP address—you’re borrowing the proxy’s. If you want to see what an e-commerce site looks like from Germany, you simply route your request through a German proxy. The website sees a request coming from a German IP address and shows you the German version of the site, complete with local pricing, products, and language. For tasks like scraping geo-restricted content with a proxy, using residential proxies for web scraping is key, as you appear to be a genuine local user.
For many, the most compelling reason to do this is simple: finding a better deal. It’s a well-known fact that prices for flights, software, and even physical goods can vary dramatically from one country to another. By using proxies located in different regions, you can comparison shop on a global scale to find the lowest possible price. This powerful capability might make you wonder about the cost of such a service, and whether you can get the same benefits for free.
The True Cost of “Free”: Why You Should Avoid Free Proxies
After learning what proxies can do, the idea of a “free” one sounds amazing. Why pay when you can get the same benefits for nothing? Unfortunately, on the internet, an old saying holds true: if you aren’t paying for the product, you are the product. Using a free proxy is like handing your mail to a complete stranger on the street and asking them to forward it. You have no idea who they are, what they’ll do with your mail, or if it will even arrive.
The biggest of all proxy risks is security. When you use a proxy, all of your internet traffic—every site you visit, every form you fill out—passes through their server. A shady free proxy provider can easily monitor this traffic, just like that stranger reading your mail before sending it. They could steal your login details, personal information, or even inject their own ads into the websites you visit. When asking are free proxies safe for scraping, the answer is almost always a resounding no, as your data is completely exposed.
Even if you find a free proxy that isn’t malicious, you’ll immediately run into another problem: it probably won’t work for your task. Because these proxies are public, thousands of people are using them at the same time, making them incredibly slow and overloaded. More importantly, major websites are experts at identifying and blocking these known public proxies. This means most free proxies for web scraping are on a proxy blacklist—a list of known bad addresses that are blocked on sight—making them useless before you even begin.
Ultimately, free proxies fail at their two most important jobs: keeping you safe and getting you access. They are slow, unreliable, and potentially dangerous. This is why even small personal projects rely on paid proxy services. Paying for a proxy isn’t just about better performance; it’s about buying security, reliability, and peace of mind. While the basic datacenter and residential proxies cover most needs, some advanced tasks require even more specialized tools.
Beyond the Basics: What Are Mobile and ISP Proxies?
Sometimes, even a residential proxy isn’t convincing enough, especially for highly protected websites like social media apps. Think about how you use the internet on your phone—that connection comes from a mobile carrier like AT&T or Verizon. A mobile proxy gives your scraper a “phone” identity, using an IP address from one of these cellular networks. Because websites are extremely hesitant to block mobile IPs (it could lock out thousands of real users), these proxies are the ultimate key for accessing data from platforms like Instagram or TikTok. Using mobile proxies for social media APIs is like having a VIP pass that websites rarely question.
Now, imagine you need that high level of trust but also require the raw speed of a datacenter proxy. This is where ISP proxies enter the picture. Think of them as a powerful hybrid: they are technically hosted in datacenters for maximum speed, but the IP addresses they use are officially registered to major Internet Service Providers (ISPs) like Comcast or Spectrum. When comparing an ISP proxy vs residential proxy, the ISP proxy offers a unique advantage. It looks like a legitimate home internet connection to the target website but performs with the speed of a commercial server, making it perfect for time-sensitive tasks like tracking limited-stock products.
Both mobile and ISP proxies are considered advanced proxies for a reason. They solve very specific, difficult challenges and typically come at a higher price. You won’t need them for every project, but for the most demanding scraping jobs, they are the most powerful tools in the box. However, your IP address is only one part of your online disguise. The other half is what your browser tells a website about itself, which is where something called a “user-agent” comes in.
The Other Half of the Disguise: What Is a User-Agent?
Changing your IP address with a proxy is like putting on a mask, but your disguise isn’t complete. Every time your browser connects to a website, it sends a little introductory note called a User-Agent. This note, part of the technical information known as http headers, tells the site what device and browser you’re using—for instance, “I am a Chrome browser on a Windows desktop” or “I am Safari on an iPhone.” It’s the other half of your digital identity that websites can see.
Websites pay close attention to this detail because they use the User-Agent to check if your story adds up. Imagine you’re using a mobile proxy, which makes it look like you’re on a smartphone in Chicago. If your User-Agent then announces that you’re using a desktop computer, it’s an immediate red flag. This inconsistency is one of the fastest ways to get blocked, as it strongly suggests your traffic is automated and not from a real, everyday user.
For successful web scraping without getting banned, your disguise must be consistent. This means your proxy type and your User-Agent have to match. If you use a residential proxy, your User-Agent should look like a standard home computer’s browser. Smart scraping tools often handle this automatically through user-agent rotation and proxy usage management, ensuring you always present a believable profile. Now that you understand the two key parts of your online disguise, the next logical question is: how do you actually put them all to work?
How Do You Actually Use a Proxy with Scraping Tools?
This might be the most relieving part of the entire process: you don’t need to be a technical wizard to start using a proxy. Think of it less like installing complex software and more like logging into your Netflix account on a new TV. You aren’t building anything; you’re simply telling your scraping tool to use a different internet connection by providing it with the right login details in its settings. The proxy setup is fundamentally a configuration step, not a programming challenge.
Once you subscribe to a proxy service, you’ll be given a set of credentials, which act as the key to your new digital identity. These credentials almost always consist of four pieces of information: the proxy server’s IP address (its location), a port number (like an apartment number at that address), a username, and a password. Whether you are using advanced frameworks or just beginning to learn about using proxies with Python and Beautiful Soup, the concept is the same. You copy these four details and paste them into the appropriate fields within your scraping tool’s network settings.
With those details in place, your tool automatically handles the rest. Every request it makes will be routed through the proxy server you specified, effectively wearing the disguise you’ve chosen. The website you’re scraping will see the proxy’s IP address, not yours. But what happens when you’ve entered everything correctly and still see a dreaded error message like “Connection Refused”? This isn’t necessarily your fault, and it’s a common hurdle when working with proxies.
“Connection Refused”: What to Do When Your Proxy Fails
Seeing an error message after carefully setting up your proxy can feel like a step backward, but these messages are actually helpful clues. Think of them like notifications from the postal service. A “Connection Refused” error is like being told the address you’re sending a letter to doesn’t exist; you likely mistyped the proxy’s IP or port number. An error like “Timeout” is a bit different; it’s like the mail carrier waited at the address, but no one ever came to the door. This often means the proxy server is offline or too slow. Effective troubleshooting common proxy errors starts with learning to translate these signals.
More often than not, a proxy connection failed message points to a simple clerical error. The most common culprit is a mistake in the credentials you entered. It’s the digital equivalent of mistyping your Wi-Fi password by one character—the network is working perfectly, but you can’t get on because your key is wrong. Another frequent issue is related to your account status. Your proxy subscription may have expired, or you might have used up your monthly data allowance. In these cases, the proxy provider has essentially “disconnected” your access, and no amount of fiddling with settings on your end will fix it.
Before diving into complex settings, your first and most important troubleshooting step is to return to your proxy provider’s dashboard. Log into their website and check two things: first, confirm that your plan is active and has resources available. Second, carefully copy and paste the proxy credentials directly from their site into your tool again to eliminate any typos. Sometimes, a website will immediately block your proxy, resulting in a “403 Forbidden” message during scraping. If your credentials and plan are correct, this simply means that specific proxy address has been flagged. Your provider’s dashboard will often let you grab a new one to try.
Scraping Responsibly: A Quick Guide to Ethical Data Gathering
Using a proxy gives you better access, but it doesn’t give you a free pass to ignore a website’s rules. Think of it like this: just because you can enter a public library doesn’t mean you can run through the aisles shouting. Most websites have a simple text file, called robots.txt, that acts as a “Welcome, here are the rules” sign for automated visitors. Before you begin, checking this file is the first step in responsible robots.txt scraping; it shows respect for the site owner’s wishes and helps you avoid immediate blocks.
Beyond a site’s explicit rules, one of the most important ethical considerations of using proxies is your speed. Imagine a small shop with one employee; if a hundred people rush the counter at once, the whole system grinds to a halt. Sending hundreds of rapid-fire requests to a website does the same thing, potentially slowing it down or even crashing it for regular users. True responsible data extraction involves building small, polite delays between your requests to mimic human browsing and avoid overwhelming the server you are visiting.
Finally, there’s a clear line between public and private information. Scraping publicly available data, like product prices, flight schedules, or business addresses, is a common and generally accepted practice. However, you should never attempt to scrape data that is behind a login, such as user profiles, private messages, or account information. This crosses a serious ethical and legal boundary. With these simple guidelines in mind, you’re now ready to think about putting proxies to use in a safe and respectful way.
Your First Scraping Project: A Simple Proxy Checklist
An “Access Denied” message is not a dead end, but a signal that a website has recognized the same digital address too many times. You now have a strategy for navigating these obstacles: using proxies as a set of disguises to gather information without being unfairly stopped.
This quick-check guide will help you decide which proxy to use for your project.
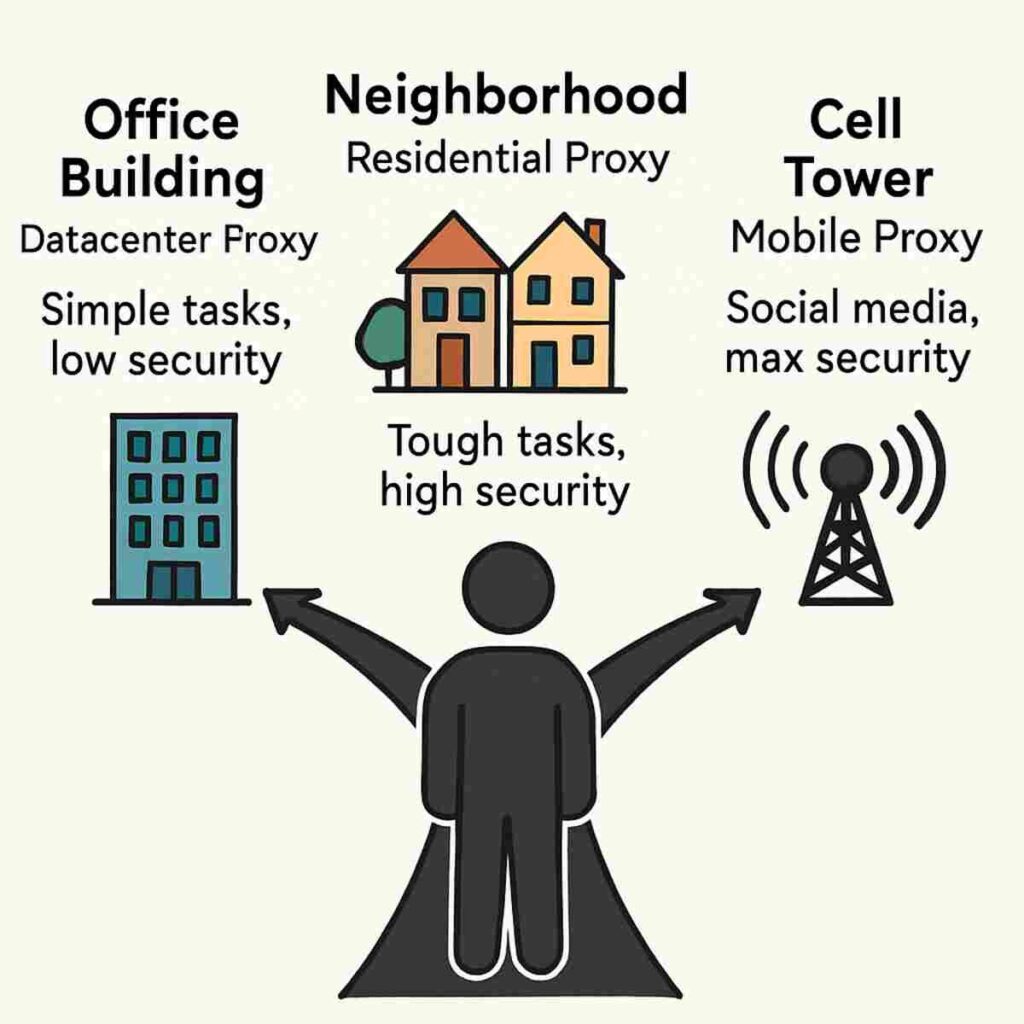
- For scraping simple sites like blogs: A few datacenter proxies are likely all you need.
- For scraping e-commerce sites with thousands of prices: You’ll need rotating residential proxies to appear as many different shoppers.
- For scraping high-security social media sites: Your best bet is rotating residential or mobile proxies, which websites trust the most.
- For just learning and experimenting: Start with a small, affordable residential proxy plan. This is the safest way to test the waters.
Your first step isn’t about finding the perfect tool; it’s about taking action and building confidence. By starting with a small, paid plan, you can safely experiment and see for yourself how a proxy changes the game. The next time you see a block, you won’t feel stuck—you’ll simply know it’s time to choose a different disguise and carry on.